Clustering Bustabit Gambling Behavior 💷
1. A preliminary look at the Bustabit data
The similarities and differences in the behaviors of different people have long been of interest, particularly in psychology and other social science fields. Understanding human behavior in particular contexts can help us to make informed decisions. Consider a game of poker - understanding why players raise, call, and fold in various situations can provide a distinct advantage competitively.
Along these lines, we are going to focus on the behavior on online gamblers from a platform called Bustabit. There are a few basic rules for playing a game of Bustabit:
- You bet a certain amount of money (in Bits, which is 1 / 1,000,000th of a Bitcoin) and you win if you cash out before the game busts.
-
Your win is calculated by the multiplier value at the moment you cashed out. For example, if you bet 100 and the value was 2.50x at the time you cashed out, you win 250. In addition, a percentage
Bonusper game is multiplied with your bet and summed to give your finalProfitin a winning game. Assuming aBonusof 1%, yourProfitfor this round would be(100 x 2.5) + (100 x .01) - 100 = 151 - The multiplier increases as time goes on, but if you wait too long to cash out, you may bust and lose your money.
- Lastly, the house maintains slight advantages because in 1 out of every 100 games, everyone playing busts.
Below we see an example of a winning game:
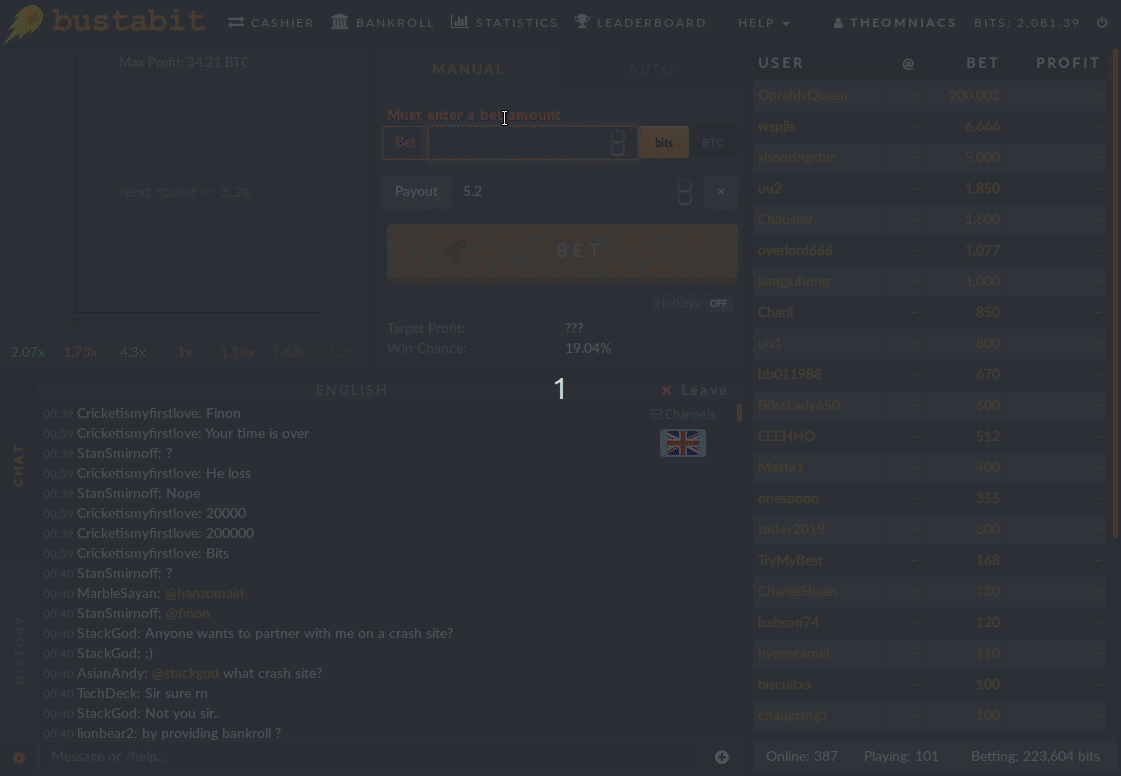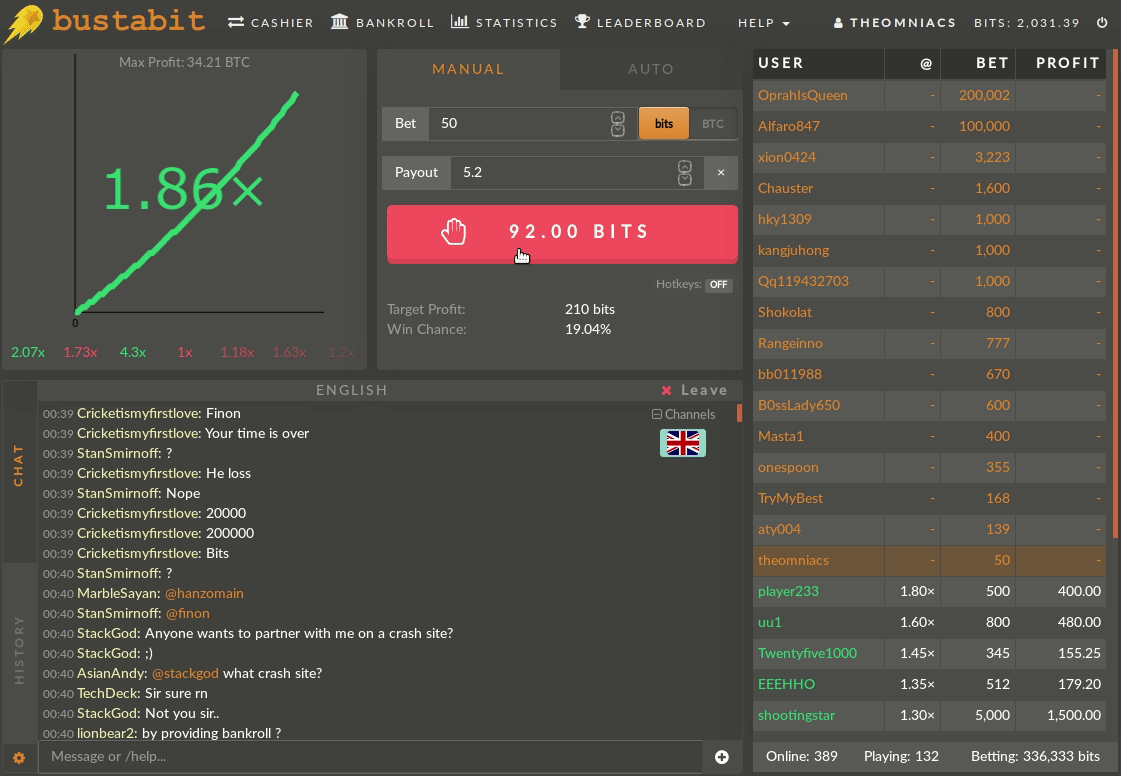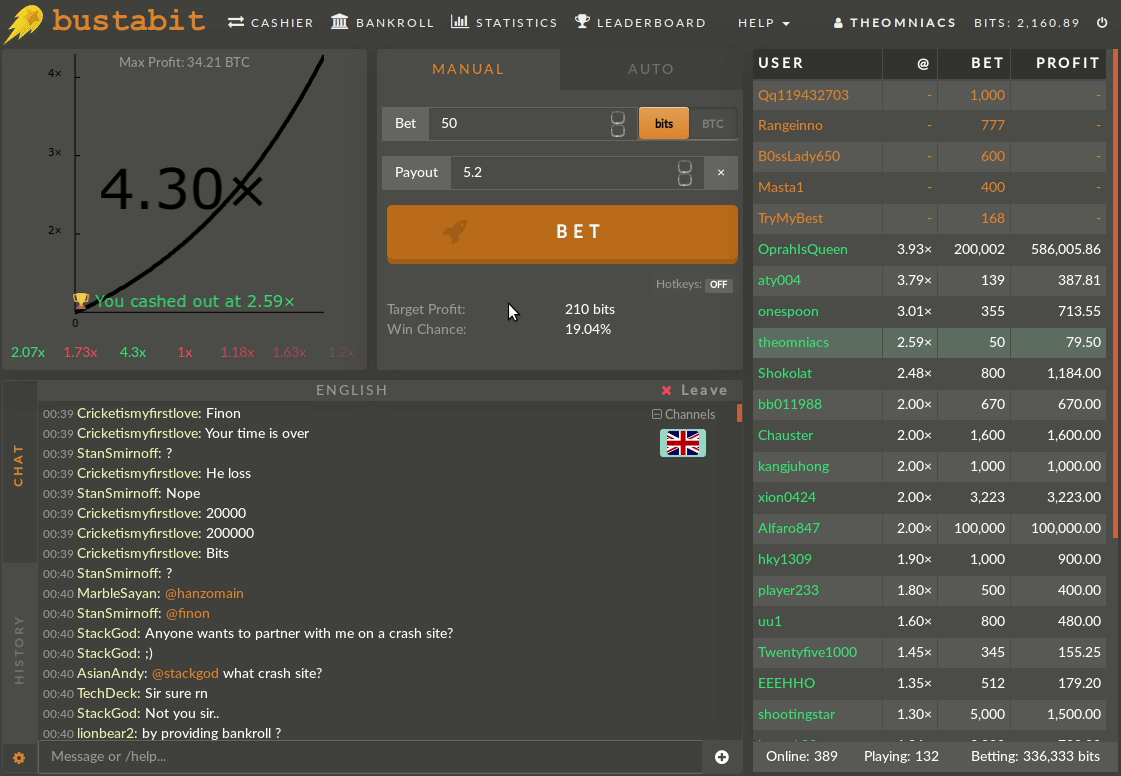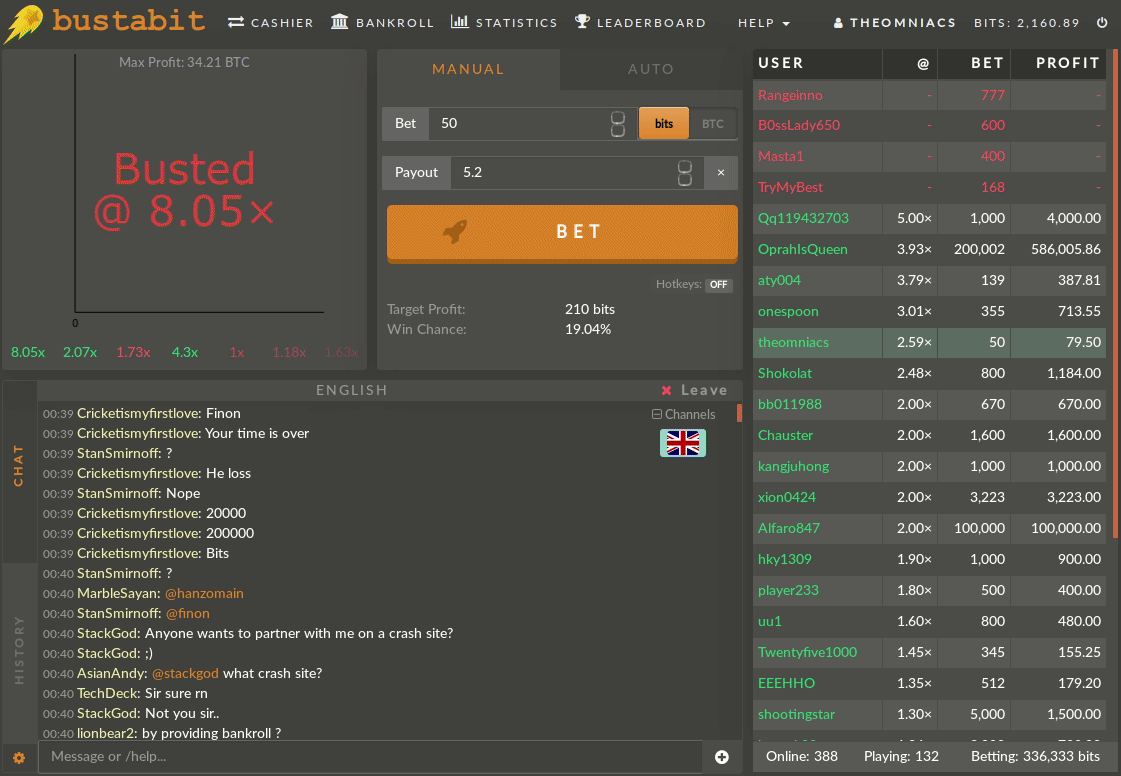
And a losing game, for comparison:
Our goal will be to define relevant groups or clusters of Bustabit users to identify what patterns and behaviors of gambling persist. Can we describe a particular group as risk-averse? Is there a set of gamblers that have a strategy that seems to be more successful in the long term?
The data you will be working with includes over 40000 games of Bustabit by a bit over 4000 different players, for a total of 50000 rows (one game played by one player). The data includes the following variables:
- Id - Unique identifier for a particular row (game result for one player)
- GameID - Unique identifier for a particular game
- Username - Unique identifier for a particular player
- Bet - The number of Bits (1 / 1,000,000th of a Bitcoin) bet by the player in this game
- CashedOut - The multiplier at which this particular player cashed out
- Bonus - The bonus award (in percent) awarded to this player for the game
- Profit - The amount this player won in the game, calculated as (Bet * CashedOut) + (Bet * Bonus) - Bet
- BustedAt - The multiplier value at which this game busted
- PlayDate - The date and time at which this game took place
Let’s begin by doing an exploratory dive into the Bustabit data!
# Load the tidyverse
library(tidyverse)
# Read in the bustabit gambling data
bustabit <- read_csv("datasets/bustabit.csv")
# Look at the first five rows of the data
head(bustabit)
## # A tibble: 6 × 9
## Id GameID Username Bet CashedOut Bonus Profit BustedAt
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 14196549 3366002 papai 5 1.2 0 1 8.24
## 2 10676217 3343882 znay22 3 NA NA NA 1.4
## 3 15577107 3374646 rrrrrrrr 4 1.33 3 1.44 3.15
## 4 25732127 3429241 sanya1206 10 NA NA NA 1.63
## 5 17995432 3389174 ADM 50 1.5 1.4 25.7 2.29
## 6 14147823 3365723 afrod 2 NA NA NA 1.04
## # … with 1 more variable: PlayDate <dttm>
# Find the highest multiplier (BustedAt value) achieved in a game
bustabit %>%
arrange(desc(BustedAt)) %>%
slice(1)
## # A tibble: 1 × 9
## Id GameID Username Bet CashedOut Bonus Profit BustedAt
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 19029273 3395044 Shadowshot 130 2 2.77 134. 251025.
## # … with 1 more variable: PlayDate <dttm>2. Deriving relevant features for clustering
The Bustabit data provides us with many features to work with, but to better quantify player behavior, we need to derive some more variables. Currently, we have a Profit column which tells us the amount won in that game, but no indication of how much was lost if the player busted, and no indicator variable quantifying whether the game itself was a win or loss overall. Hence, we will derive or modify the following variables:
-
CashedOut - If the value for
CashedOutisNA, we will set it to be 0.01 greater than theBustedAtvalue to signify that the user failed to cash out before busting -
Profit - If the value for
ProfitisNA, we will set it to be zero to indicate no profit for the player in that game -
Losses - If the new value for
Profitis zero, we will set this to be the amount the player lost in that game, otherwise we will set it to zero. This value should always be zero or negative - GameWon - If the user made a profit in this game, the value should be 1, and 0 otherwise
- GameLost If the user had a loss in this game, the value should be 1, and 0 otherwise
# Create the new feature variables
bustabit_features <- bustabit %>%
mutate(CashedOut = ifelse(is.na(CashedOut), BustedAt + .01, CashedOut),
Profit = ifelse(is.na(Profit), 0, Profit),
Losses = ifelse(Profit == 0, -1*Bet, 0),
GameWon = ifelse(Profit != 0, 1, 0),
GameLost = ifelse(Profit == 0, 1, 0))
# Look at the first five rows of the features data
head(bustabit_features)
## # A tibble: 6 × 12
## Id GameID Username Bet CashedOut Bonus Profit BustedAt
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 14196549 3366002 papai 5 1.2 0 1 8.24
## 2 10676217 3343882 znay22 3 1.41 NA 0 1.4
## 3 15577107 3374646 rrrrrrrr 4 1.33 3 1.44 3.15
## 4 25732127 3429241 sanya1206 10 1.64 NA 0 1.63
## 5 17995432 3389174 ADM 50 1.5 1.4 25.7 2.29
## 6 14147823 3365723 afrod 2 1.05 NA 0 1.04
## # … with 4 more variables: PlayDate <dttm>, Losses <dbl>, GameWon <dbl>,
## # GameLost <dbl>3. Creating per-player statistics
The primary task at hand is to cluster Bustabit players by their respective gambling habits. Right now, however, we have features at the per-game level. The features we’ve derived would be great if we were interested in clustering properties of the games themselves - we know things about the BustedAt multiplier, the time the game took place, and lots more. But to better quantify player behavior, we must group the data by player (Username) to begin thinking about the relationship and similarity between groups of players. Some per-player features we will create are:
- AverageCashedOut - The average multiplier at which the player cashes out
- AverageBet - The average bet made by the player
- TotalProfit - The total profits over time for the player
- TotalLosses - The total losses over time for the player
- GamesWon - The total number of individual games the player won
- GamesLost - The total number of individual games the player lost
With these variables, we will be able to potentially group similar users based on their typical Bustabit gambling behavior.
# Group by players to create per-player summary statistics
bustabit_clus <- bustabit_features %>%
group_by(Username) %>%
summarize(AverageCashedOut = mean(CashedOut),
AverageBet = mean(Bet),
TotalProfit = sum(Profit),
TotalLosses = sum(Losses),
GamesWon = sum(GameWon),
GamesLost = sum(GameLost))
# View the first five rows of the data
head(bustabit_clus, n = 5)
## # A tibble: 5 × 7
## Username AverageCashedOut AverageBet TotalProfit TotalLosses GamesWon
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 _caramba_tm_ 1.7 1.33 3.13 0 3
## 2 _Dear_ 1.66 215 0 -860 0
## 3 _lsx 1.20 6282 3545. -2000 4
## 4 _noBap_ 6.58 4 0 -4 0
## 5 _TechDeck 1.19 6 0 -6 0
## # … with 1 more variable: GamesLost <dbl>4. Scaling and normalization of the derived features
The variables are on very different scales right now. For example, AverageBet is in bits (1/1000000 of a Bitcoin), AverageCashedOut is a multiplier, and GamesLost and GamesWon are counts. As a result, we would like to normalize the variables such that across clustering algorithms, they will have approximately equal weighting.
One thing to think about is that in many cases, we may actually want a particular numeric variable to maintain a higher weight. This could occur if there is some prior knowledge regarding, for example, which variable might be most important in terms of defining similar Bustabit behavior. In this case, without that prior knowledge, we will forego the weighting of variables and scale everything. We are going to use mean-sd standardization to scale the data. Note that this is also known as a Z-score.
Note that we could compute the Z-scores by using the base R function scale(), but we’re going to write our own function in order to get the practice.
# Create the mean-sd standardization function
mean_sd_standard <- function(x) {
(x - mean(x))/sd(x)
}
# Apply the function to each numeric variable in the clustering set
bustabit_standardized <- bustabit_clus %>%
mutate_if(is.numeric, mean_sd_standard)
# Summarize our standardized data
summary(bustabit_standardized)
## Username AverageCashedOut AverageBet TotalProfit
## Length:4149 Min. :-0.76289 Min. :-0.1773 Min. :-0.09052
## Class :character 1st Qu.:-0.28157 1st Qu.:-0.1765 1st Qu.:-0.09050
## Mode :character Median :-0.18056 Median :-0.1711 Median :-0.08974
## Mean : 0.00000 Mean : 0.0000 Mean : 0.00000
## 3rd Qu.: 0.02752 3rd Qu.:-0.1384 3rd Qu.:-0.08183
## Max. :41.72651 Max. :24.9971 Max. :40.73652
## TotalLosses GamesWon GamesLost
## Min. :-41.84541 Min. :-0.4320 Min. :-0.41356
## 1st Qu.: 0.09837 1st Qu.:-0.3696 1st Qu.:-0.41356
## Median : 0.10847 Median :-0.3071 Median :-0.33306
## Mean : 0.00000 Mean : 0.0000 Mean : 0.00000
## 3rd Qu.: 0.10916 3rd Qu.:-0.1196 3rd Qu.:-0.09156
## Max. : 0.10916 Max. :13.2534 Max. :19.309115. Cluster the player data using K means
With standardized data of per-player features, we are now ready to use K means clustering in order to cluster the players based on their online gambling behavior. K means is implemented in R in the kmeans() function from the stats package. This function requires the centers parameter, which represents the number of clusters to use.
Without prior knowledge, it is often difficult to know what an appropriate choice for the number of clusters is. We will begin by choosing five. This choice is rather arbitrary, but represents a good initial compromise between choosing too many clusters (which reduces the interpretability of the final results), and choosing too few clusters (which may not capture the distinctive behaviors effectively). Feel free to play around with other choices for the number of clusters and see what you get instead!
One subtlety to note - because the K means algorithm uses a random start, we are going to set a random seed first in order to ensure the results are reproducible.
# Choose 20190101 as our random seed
set.seed(20190101)
# Cluster the players using kmeans with five clusters
cluster_solution <- kmeans(bustabit_standardized[,-1], centers = 5)
# Store the cluster assignments back into the clustering data frame object
bustabit_clus$cluster <- factor(cluster_solution$cluster)
# Look at the distribution of cluster assignments
table(bustabit_clus$cluster)
##
## 1 2 3 4 5
## 3626 17 412 16 786. Compute averages for each cluster
We have a clustering assignment which maps every Bustabit gambler to one of five different groups. To begin to assess the quality and distinctiveness of these groups, we are going to look at group averages for each cluster across the original variables in our clustering dataset. This will, for example, allow us to see which cluster tends to make the largest bets, which cluster tends to win the most games, and which cluster tends to lose the most money. This will provide us with our first clear indication as to whether the behaviors of the groups appear distinctive!
# Group by the cluster assignment and calculate averages
bustabit_clus_avg <- bustabit_clus %>%
group_by(cluster) %>%
summarize_if(is.numeric, mean)
# View the resulting table
bustabit_clus_avg
## # A tibble: 5 × 7
## cluster AverageCashedOut AverageBet TotalProfit TotalLosses GamesWon GamesLost
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 1.70 4024. 4273. -4366. 2.91 2.13
## 2 2 27.4 1278. 619. -581. 0.706 1.53
## 3 3 1.92 1633. 19363. -19205. 27.1 21.0
## 4 4 2.47 298946. 1198191. -1056062. 10.6 8.06
## 5 5 1.76 432. 18568. -16724. 87.2 61.27. Visualize the clusters with a Parallel Coordinate Plot
We can already learn a bit about our cluster groupings by looking at the previous table. We can clearly see that there is a group that makes very large bets, a group that tends to cash out at very high multiplier values, and a group that has played many games of Bustabit. We can visualize these group differences graphically using a Parallel Coordinate Plot or PCP. To do so, we will introduce one more kind of scaling: min-max scaling, which forces each variable to fall between 0 and 1.
Other choices of scaling, such as the Z-score method from before, can work effectively as well. However, min-max scaling has the advantage of interpretability - a value of 1 for a particular variable indicates that cluster has the highest value compared to all other clusters, and a value of 0 indicates that it has the lowest. This can help make relative comparisons between the clusters more clear.
The ggparcoord() function from GGally will be used to produce a Parallel Coordinate Plot. Note that this has a built-in argument scale to perform different scaling options, including min-max scaling. We will set this option to “globalminmax” to perform no scaling, and write our own scaling routine for practice. If you are interested, you can look at the function definition for ggparcoord() to help you write our scaling function!
# Create the min-max scaling function
min_max_standard <- function(x) {
(x - min(x))/(max(x) - min(x))
}
# Apply this function to each numeric variable in the bustabit_clus_avg object
bustabit_avg_minmax <- bustabit_clus_avg %>%
mutate_if(is.numeric, min_max_standard)
# Load the GGally package
library(GGally)
## Registered S3 method overwritten by 'GGally':
## method from
## +.gg ggplot2
# Create a parallel coordinate plot of the values
ggparcoord(bustabit_avg_minmax, columns = 2:ncol(bustabit_avg_minmax),
groupColumn = NULL, scale = "globalminmax", order = "skewness")
8. Visualize the clusters with Principal Components
One issue with plots like the previous is that they get more unwieldy as we continue to add variables. One way to solve this is to use the Principal Components of a dataset in order to reduce the dimensionality to aid in visualization. Essentially, this is a two-stage process:
- We extract the principal components in order to reduce the dimensionality of the dataset so that we can produce a scatterplot in two dimensions that captures the underlying structure of the higher-dimensional data.
- We then produce a scatterplot of each observation (in this case, each player) across the two Principal Components and color according to their cluster assignment in order to visualize the separation of the clusters.
This plot provides interesting information in terms of the similarity of any two players. In fact, you will see that players who fall close to the boundaries of clusters might be the ones that exhibit the gambling behavior of a couple of different clusters. After you produce your plot, try to determine which clusters seem to be the most “different.” Also, try playing around with different projections of the data, such as PC3 vs. PC2, or PC3 vs. PC1, to see if you can find one that better differentiates the groups.
# Calculate the principal components of the standardized data
my_pc <- as.data.frame(prcomp(bustabit_standardized[,-1])$x)
# Store the cluster assignments in the new data frame
my_pc$cluster <- bustabit_clus$cluster
# Use ggplot() to plot PC2 vs PC1, and color by the cluster assignment
p1 <- ggplot(data = my_pc , aes(x = PC1, y = PC2, color = cluster)) + geom_point()
# View the resulting plot
p1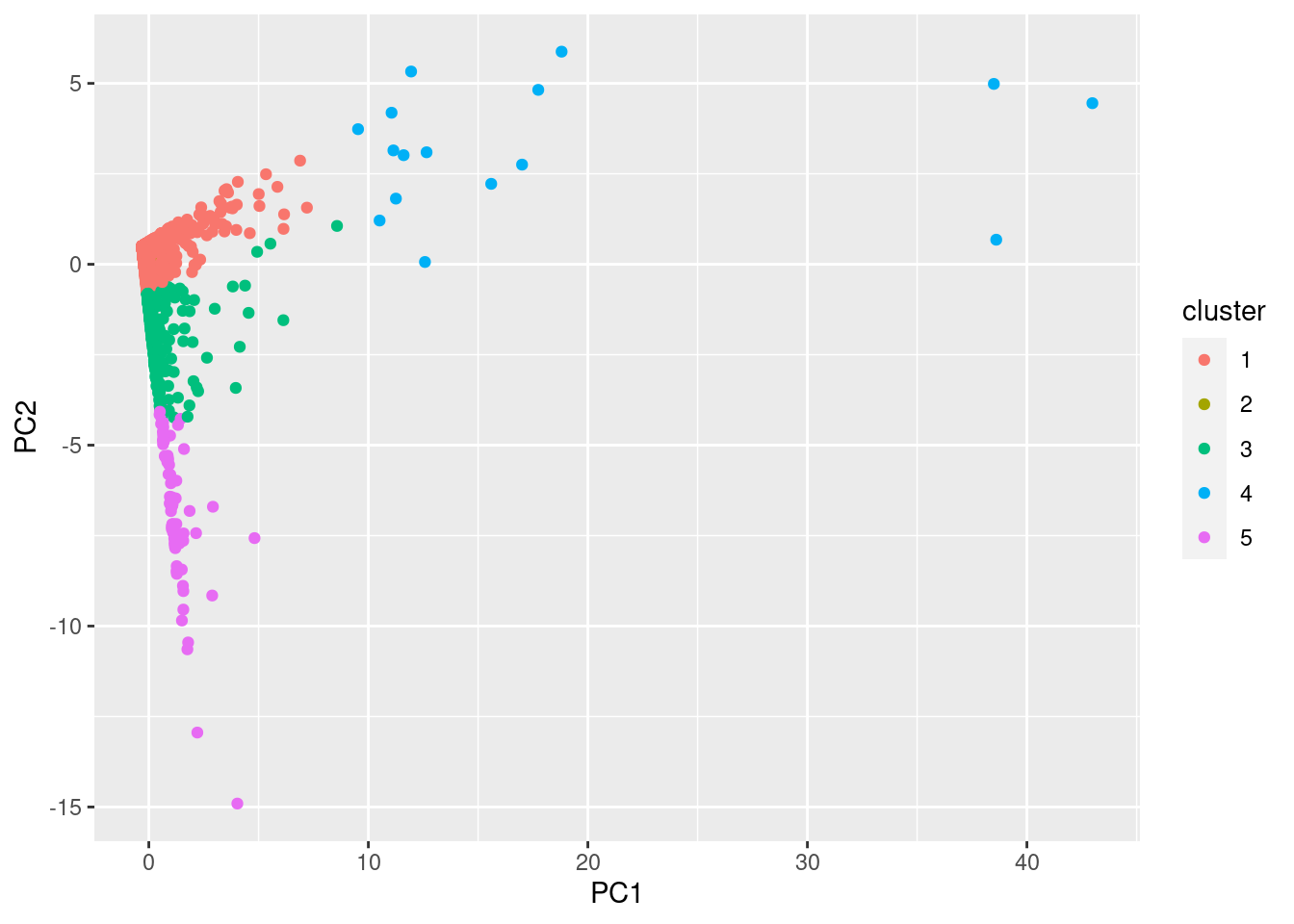
9. Analyzing the groups of gamblers our solution uncovered
Though most of the statistical and programmatical work has been completed, possibly the most important part of a cluster analysis is to interpret the resulting clusters. This often is the most desired aspect of the analysis by clients, who are hoping to use the results of your analysis to inform better business decision making and actionable items. As a final step, we’ll use the parallel coordinate plot and cluster means table to interpret the Bustabit gambling user groups! Roughly speaking, we can breakdown the groups as follows:
Cautious Commoners:
Strategic Addicts:
Risky Commoners:
Risk Takers:
High Rollers:
# Assign cluster names to clusters 1 through 5 in order
cluster_names <- c(
"Risky Commoners",
"High Rollers",
"Risk Takers",
"Cautious Commoners",
"Strategic Addicts"
)
# Append the cluster names to the cluster means table
bustabit_clus_avg_named <- bustabit_clus_avg %>%
cbind(Name = cluster_names)
# View the cluster means table with your appended cluster names
bustabit_clus_avg_named
## cluster AverageCashedOut AverageBet TotalProfit TotalLosses GamesWon
## 1 1 1.699993 4024.1102 4272.6656 -4365.7788 2.9109211
## 2 2 27.448235 1278.2574 619.4041 -581.2941 0.7058824
## 3 3 1.915776 1633.2292 19362.9909 -19205.1165 27.0606796
## 4 4 2.470024 298945.6618 1198191.1631 -1056062.1875 10.5625000
## 5 5 1.758407 432.1163 18568.1141 -16724.0641 87.1794872
## GamesLost Name
## 1 2.128792 Risky Commoners
## 2 1.529412 High Rollers
## 3 21.036408 Risk Takers
## 4 8.062500 Cautious Commoners
## 5 61.205128 Strategic Addicts